看了一下發文記錄,這應該是此格在停業六年後重新生出來的文章,就... 留個記錄吧!
我是在 2016 年時開始接觸容器應用的,不過實務上一直沒啥機會應用。後來在前公司的 2017 年計劃中原本有一項重點是預訂將營業相關的應用系統自單機移轉到雲端上(因為服務是面向全球),但公司停業了(所以我失業了),這項計劃也就不了了之。
營業系統的核心架構是 APIs + MySQL,原本是在 Google 上開設兩台 VM 各司其職,實務上它並不具有 Non Stopping 的服務等級要求,也就是說若 API Server 或 MySQL 資料庫崩潰了,在管理人員進行修正前服務都是停擺的。
這次選擇的是雲端平台是 Google Cloud Platform,理由只是因為它直接提供了 Cloud SQL for MySQL,在資料量不多的情況下相信可以直接透過 mysqldump 無痛轉移資料庫內容。
示範平台
本案範例是在 macOS Sierra 上進行驗證,系統上包含了 Docker for Mac 17.06.0-ce、Java SDK 1.8.0_102、以及 MySQL Client for 5.7.17。Java 打包工具則為 Apache Maven 3.5.0,但應該 3.x 以上版本都能適用。
Google 針對 Google Cloud Platform (以下稱 GCP)提供了 12 個月 300 美金的試用額度,這對於懶人測試員有很大的誘因,如果你不想在 2 ~ 3 星期內完成一大堆的測試,那麼 GCP 可以讓你安心的將測試項目安排在 52 星期內慢慢進行... XD
GCP 透過專案的概念協助管理人員於單一介面內管理與專案有關的各種 Google 服務,所以第一個就是建立 GCP 專案,上圖中紅框部份都能進入建立 GCP 專案的流程。
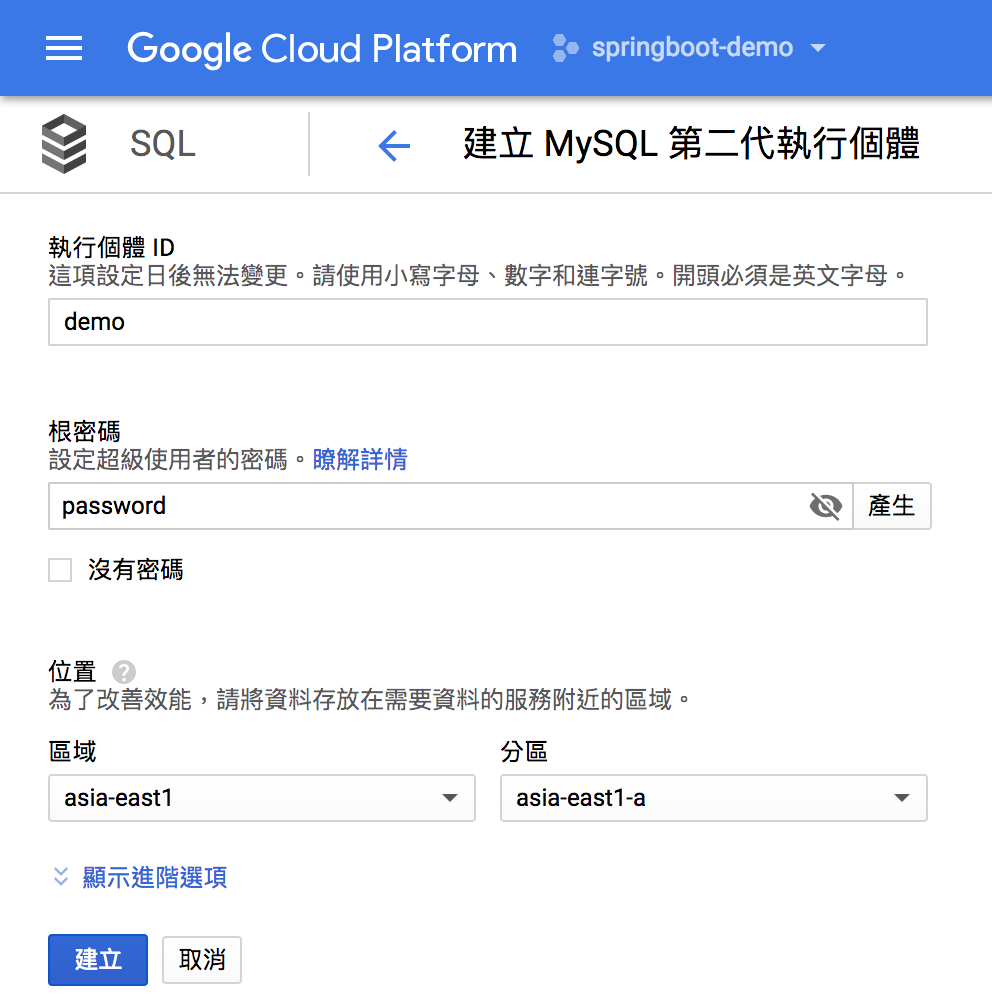
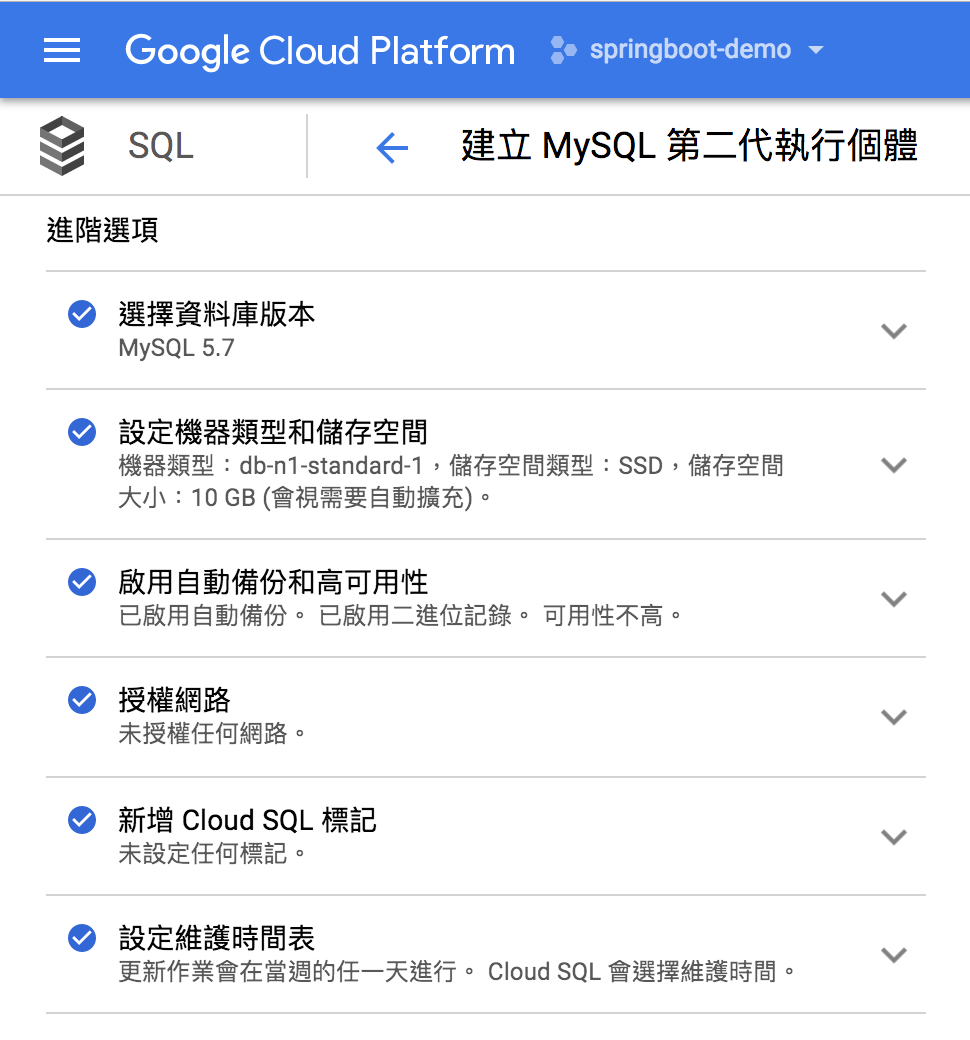
在 Cloud SQL 上建立一個 MySQL 資料庫很簡單,除了透過 Google Cloud SDK 以指令方式建立外,還可以透過 Cloud Console UI 建立。
- 主資料庫
- 容錯資料庫
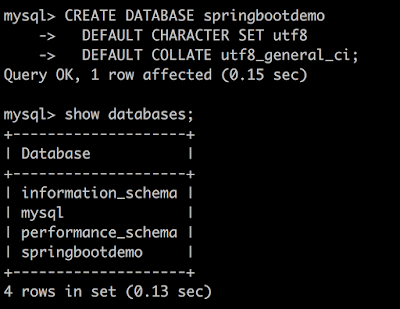
建立空白資料庫
為了後續測試所需,此時先在主資料庫 demo 上建立一個空白資料庫,名稱為 springbootdemo,這個資料庫會自動複製到容錯資料庫 demo-failover 去。
CREATE DATABASE springbootdemo
DEFAULT CHARACTER SET utf8
DEFAULT COLLATE utf8_general_ci;
IP 參照設定
Spring Boot 示範程式
再來是開發一個可以存取 Cloud SQL for MySQL 的應用程序,這裡選擇使用
Spring Boot 開發框架。
選擇 Spring Boot 的理由主要是因為它可以整合 Tomcat 這類型的 Application Server,當我們需要將服務置入 Docker Container 中執行時就可以不必額外處理 Tomcat 在各種不同 Linux 散佈套件的差異。
複製範例程式
這個範例程式的功能是模擬兩個 API,分別是
顯示被呼叫的主機名稱及
中止應用程序(模擬程序崩潰)。請自 Github 上複製
SpringBootDemo 這個專案,關於 Spring Boot 的設定細節請自行參考網路文章,此處不特別說明:
以下命令列指令可以將 SpringBootDemo 專案複製到本地工作:
git clone https://github.com/AdaHsu/SpringBootDemo.git
整個示範程式的目錄結構如下圖,需要自行調整的參數設定都在 Maven 的設定檔 pom.xml 中:

修改 Maven 設定檔
在 pom.xml 中要修改的地方有 3 個,主要和資料庫存取有關:
- local profile 下的 JDBC 連線資訊:確認已設定好 mysql.gcp 的 IP 參照,或直接將 mysql.gcp 替換為 Cloud SQL for MySQL 提供的對外 IP

- JDBC 的使用者帳密設定:一般環境下應該要建立應用程式專屬帳號
測試程式運作狀態
完成修改後即可進行功能測試,測試前請先確認 Cloud SQL for MySQL 執行個體已啟用,然後下達以下指令打包程式,-P local 是指定產生本地測試用的版本,若為 -P gcp 則會產生 GCP 上適用的版本,可以從打包出來的檔名確認對應的執行環境。
mvn -P local clean package
完成打包後會產生 target 目錄,此處已設定打包後的 jar 檔檔名會依指定的 Profile 不同而變化。

為確保程式運作正常,建議先檢查資料庫連線參數是否正確設定,此參數應與 Maven 設定檔中設定的內容一致。
head target/classes/application.properties

如果是 Windows 平台,那麼指令應該要改成如下:
type target/classes/application.properties
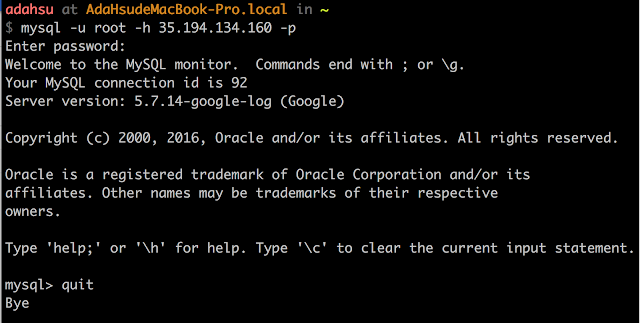
預先以 MySQL Client 連上資料庫,確認資料庫內未建立任何表格。

啟動 Spring Boot 應用程式,若 JPA 能連接資料庫的話就不會有錯誤訊息,否則就會崩潰結束。
java -jar target/SpringBootDemo-local.jar

檢視資料庫,確認 access_logs 表格已被建立出來。

驗證 API
第一個 API 的用途是將呼叫記錄寫入資料庫內,並且傳回提供服務的主機名稱,在部署到 Google Container Engine 時將用於識別是哪一個容器 / Pod 提供服務的。
curl http://localhost:8080

第二個 API 的用途是中斷 Spring Boot 應用系統的執行,目的是模擬系統異常導致服務終止的情形。
curl http://localhost:8080/crash

呼叫結束後可以確認到 Spring Boot 應用程式被終止。

檢視資料庫,確認兩次呼叫記錄已被保存。
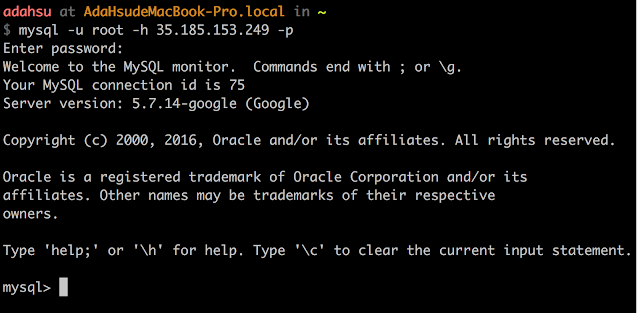
確認容錯資料庫內容也已同步更新。
echo "select * from access_logs;" | mysql -u root -h failover.gcp -p springbootdemo

打包 Docker 映像檔
從 Github 上下 clone 下來的檔案庫中包含兩個協助打包的 Dockerfile ,分別對應到打包成 local 及 gcp 兩個環境。

打包本地測試用映像檔
以下指令可以打包一個本地進行測試用的 docker image,MYSQL_IP 是記錄 /etc/hosts 中 demo.gcp 所指向 Cloud SQL for MySQL 的 Public IP,Windows 平台使用者請直接將 ${MYSQL_IP} 替換成 IP 位址即可:
MYSQL_IP=$(grep mysql.gcp /etc/hosts | cut -d\ -f 1)
docker build -t spring-boot-demo:1 \
--add-host=mysql.gcp:${MYSQL_IP} \
-f Dockerfile.local .

若是已將 pom.xml 中的 JDBC 連線字串替換成 IP 位址的話,那麼打包指令中的 --add-host 這段參數可以拿掉。
若是 Windows 平台可以直接給定 mysql.gcp 所對應的 IP,以下指令請記得替換 <mysql public ip> 為實際 IP:
docker build -t spring-boot-demo:1 --add-host=mysql.gcp:<mysql public ip> -f Dockerfile.local .
驗證映像檔
打包完畢後可以啟動這個 Container 映像檔確認是否正常運作。
docker run --rm -p 8080:8080 spring-boot-demo:1
檢視 API 是否可被呼叫?

打包 GCP 線上版本
GCP 下載 Docker Images 的來源有二:第一種是上傳到 Docker Hub,另一種方式則是上傳到專案所在的 Cloud Storage 中。上傳到 Cloud Storage 時需指定 Docker 映像檔的 Tag,格式為
gcr.io/<專案 ID>/<映像檔名>:<標籤>,其中 <專案 ID> 請參考專案資訊主頁中的
專案資訊卡片。

以下指令可以打包一個在 GCP 上運行的 Docker 映像檔,為了避免包裝映像檔失敗,此處會重新打包 Spring Boot 範例程式:
mvn -P gcp clean package
docker build -t gcr.io/springboot-demo/spring-boot-demo:1 -f Dockerfile.gcp .

稍候會將這個映像檔上傳到 Google Cloud Storage 中供 Container Engine 叫用。
建立 Google 容器叢集
Google Container Engine (GCE,有時會看到 GKE 指的是同一個服務) 是 Google 提供的容器服務,在使用容器服務之前需要建立一個用於部署容器的容器叢集。
拉出左側
產品與服務選單,點選
Container Engine 功能項後即可進入 Container Engine 資訊主頁,第一次進入這個主頁時可能需要一點時間啟用 Container Engine 服務。

有時候可能會發生沒有 Compute Engine API 權限而無法啟用 Container Engine 服務的問題,通常只要重新進入 Container Engine 資訊主頁即可改善。
建立容器叢集
在 Container Engine 資訊主頁中可以透過建立容器叢集按鈕建立新的叢集。
容器叢集基本上是透過 Compute Engine 裡頭的 VM 組建而成,它需要決定這個叢集的運作能量(財力決定能力?)。
- 設定叢集參數(一)
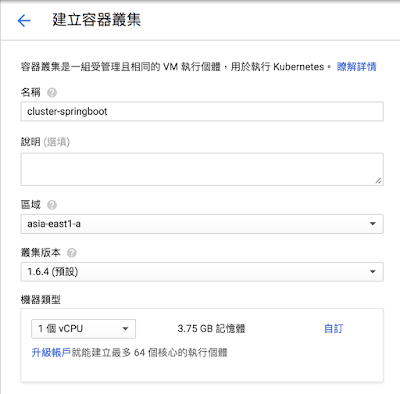
- 名稱:本叢集的名稱
- 說明:若有多個叢集共存的情形下,可以在此填寫一些說明內容
- 區域:要將叢集放在哪個機房,此處放在先前建立的 Cloud SQL for MySQL 相同的機房內
- 叢集版本:這個應該不用動
- 機器類型:視需要自行調整,老話一句:財力決定規格、規格決定能力
- 設定叢集參數(二)
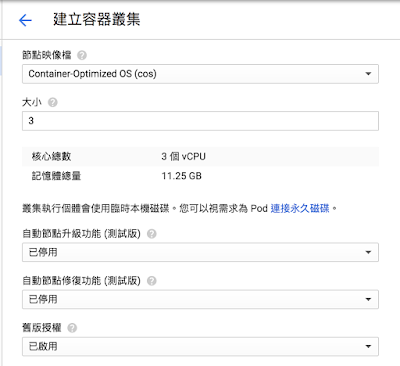
- 節點映像檔:此案單純將 VM 當成容器載體,所以都選擇 Container-Optimized OS 這種映像檔
- 大小:指的是叢集大小,也就是多少個叢集節點(主機數),此處選 3 是為了後續驗證負載平衡及應用程序崩潰時是否會影響服務之用
- 其他參數暫時不需理會,直接按建立鈕即可開始建立容器叢集
- 花一點時間(聽說 Google 優化過了,現在來不及去泡咖啡了)讓容器叢集成功建立後就可在 Container Engine 資訊主頁中看到叢集的相關資訊
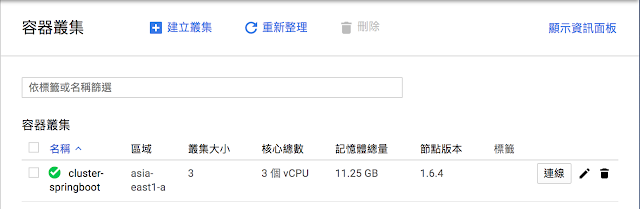
- 切換到 Compute Engine 資訊主頁中可以看到 3 個 VM 執行個體
- 可以直接在瀏覽器中連接 VM 進行操作,有瀏覽器就能進行管理(但好不好用要看平台,用手機相信是很難用就是了)
- 這是個 Kubernetes 專屬 VM,必然會看到一堆 Kubernetes 相關的容器在運作
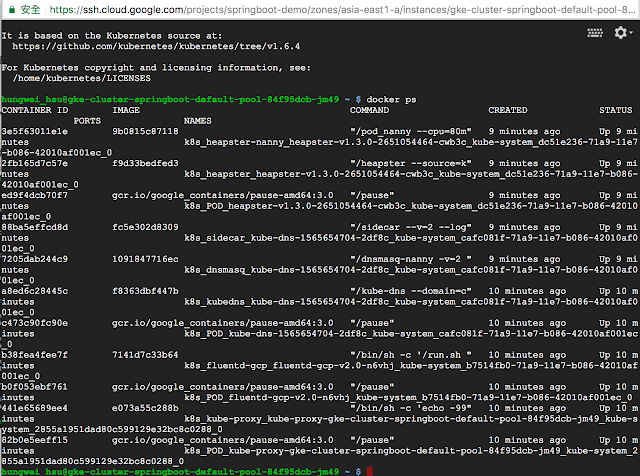
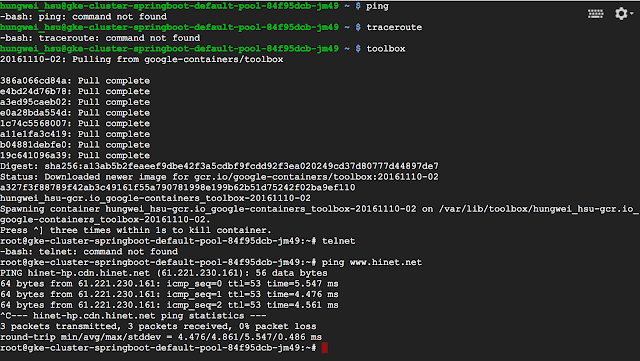
- 有些網路工具像是 ping、traceroute 等等預設是未安裝的,可以透過執行 toolbox 指令另外弄一個容器來提供這些功能
安裝 Google Cloud SDK
Google Cloud Platform 雖然是以專案方式管理某項服務所需的各種資源,例如本案中的 Cloud SQL for MySQL、Container Engine 等等,但 Cloud SQL 和 Container Engine 之間並無互通,要讓 Container 能連接上 Cloud SQL 必須透過 Cloud SQL Proxy 進行轉接。目前這些設定步驟尚無法完全透過 Web UI 加以操作,取而代之必須使用 Google Cloud SDK 進行設定。
回到專案的資訊主頁,在
入門指南這個資訊卡片下有一個『安裝 Cloud SDK』的連結,點擊它後即可取得各平台的安裝檔案(macOS 可以透過
Homebrew-Cask 安裝),請依指示完成 Cloud SDK 安裝。

初始化 Cloud SDK
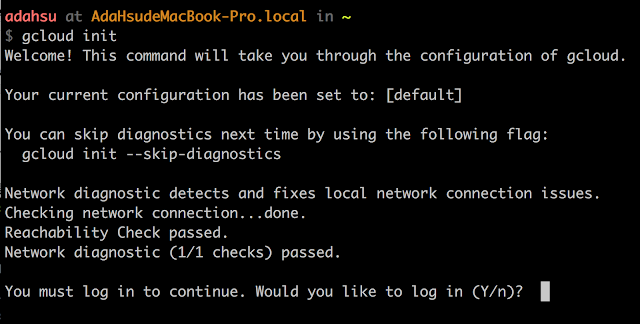
安裝完 Cloud SDK 後需要進行初始化操作以授權存取 Google Cloud Platform,指令如下:
gcloud init
- 初始化過程中會透過瀏覽器進行線上認證
- 需同意 Google Cloud SDK 這些權限

- 指定預設的專案
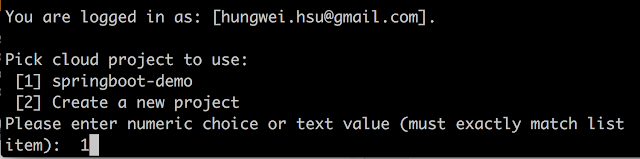
- 設定 Compute Engine 預設的機房:應該是指若是透過 Cloud SDK 指令方式建立的 VM 都會以這個設定為準,這裡選 asia-east1-a
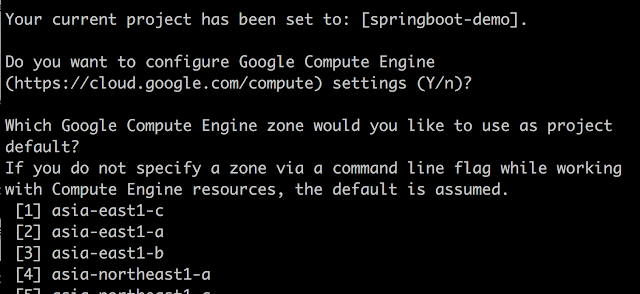
- 初始化完成後會提示目前登入的帳號、預設專案、以及預設機房

- 日後隨時可以檢視這些設定,也可以修改
gcloud config list
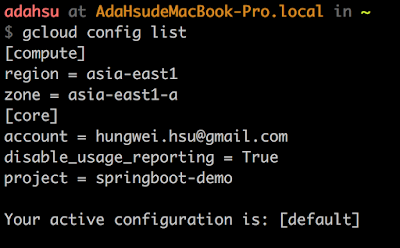
管理 Cloud SDK 設定檔
若有多個 GCP 專案,則重覆執行 init 指令即可建立相應的設定檔。

檢視目前已建立的專案 / 設定檔,新建立的設定檔會自動啟用。
gcloud config configurations list

在多個設定檔同時存在的情形下,可以依需要啟用所需設定檔:
gcloud config configurations activate <proejct id>

不需要的設定設定檔可以刪除,但不能刪除啟用中的設定檔。
gcloud config configurations delete <proejct id>

使用 Cloud SDK 進行管理 Cloud SQL
前面使用 Google Cloud Console 資訊主頁的各項操作都可以透過 Cloud SDK 完成相關設定,但是 Cloud SDK 之所以重要是因為它能讓管理人員在任何地方皆能連接 Cloud SQL for MySQL,此特性讓維運人員即使是在 4G 環境下仍然可以隨時檢視 Cloud SQL for MySQL 的資料庫狀況。
檢查專案中資料庫列表:
gcloud sql instances list

連線資料庫進行管理,為了讓管理人員隨時連線,Cloud SDK 需要一點時間調整防火牆設定:
gcloud sql connect <db instance name> -u <user name>

設定 Cloud SQL Proxy
雖然覺得很蠢,但目前想要從 Google Container Engine 連接 Cloud SQL 服務的話,必須另外設定 Proxy,帶來的好處是應用程式開發時使用的 JDBC 資料庫連線都是指向本機 localhost 的,和一般開發過程中直接連線本地 MySQL 狀況相似。以下說明皆依據
官方說明文件 進行整理,並加入個人驗證經驗。
安裝 kubernetes 管理元件
透過以下指令可以協助安裝管理 kubernetes 所需的管理元件。
gcloud components install kubectl
將 Cloud SDK 使用中的憑證授權給 kubectl 使用。
gcloud container clusters get-credentials <叢集名稱>

以下指令可以檢視 Cloud SDK 目前支援的、已安裝的元件列表。
gcloud componets list
啟用 Cloud SQL API
請透過
這個連結 啟用 Cloud SQL 管理 API,也可以從
產品與服務 -->
API 管理員 的資訊主頁中選擇啟用 Cloud SQL API。

建立服務帳號
Cloud SQL Proxy 需要一個服務帳號串接 Container 及 Compute 平台,請從 Console 的
產品與服務 -->
IAM 與管理 -->
服務帳戶 功能選項中進入,或者直接點選
這個連結 進入前述資訊主頁(需再指定專案 ID)。預設會有一個用於連接 Compute Engine 的服務帳號。
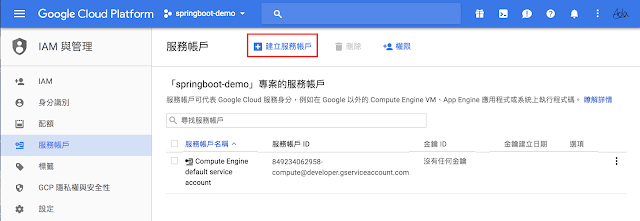
點選資訊主賈上方的
建立服務帳戶連結,填入相關資訊後按建
建立鈕。

- 服務帳戶名稱:用來識別帳戶用途的名稱,隨便取
- 角色:請選擇 Cloud SQL --> Cloud SQL 用戶端
- 服務帳號 ID:若有需要可以自行修改
- 提供一組新的私密金鑰:請勾選,並且設定金鑰類型為 JSON,在帳號建立後會下載一個金鑰檔,請妥善保存;可以使用 SERVICE_KEY_FILE 這樣的變數去記錄保存位置,之後在匯入金鑰時會參照到

取得 Cloud SQL 執行個體連線字串
透過以下指令可以取得指定 Cloud SQL 執行個體的細節資訊,此處擷取的是它的連線字串,格式是:
<專案 ID>:<區域>:<執行個體名稱>,此連線字串請標記為 CONNECTION_NAME 供後續使用。
gcloud sql instances describe <MySQL Instance Name> | grep connectionName

若是 Windows 平台那就去掉 | 及之後 grep 指令,直接用眼睛找一下 connectionName 這個關鍵字。
建立識別資訊
為了讓 Container Engine 可以連接到 Cloud SQL,必須將剛剛建立的 MySQL 用戶端服務帳號匯入 Kubernets 中讓 Cloud Proxy 可以參照到:
kubectl create secret generic cloudsql-instance-credentials \
--from-file=credentials.json=${SERVICE_KEY_FILE}

編輯 K8S 部署設定檔
在專案目錄下有一個 k8s-deploy-config.yaml 的 kubernetes 部署 (Deployment) 設定檔,可以協助在 Container Engine 中建立一個應用系統部署單位。
請修改部署設定檔中的以下設定:
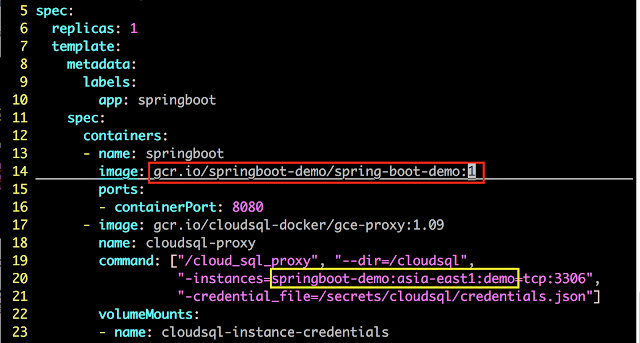
- 第 14 行的 Docker 映像檔標籤:請確認已打包成 GCP 線上版本所需設定,格式為:gcr.io/<專案 ID>/<映像檔檔名>:<標籤>
- 第 20 行的 Cloud SQL 執行個體連線字串
在 Container Engine 上啟動 Spring Boot 應用程式
完成前述設定後會得到兩個檔案:一個給 GCP 啟動用的 Docker 映像檔及一個給 Kubernetes 啟動部署作業所需的設定檔。第一件事就是將 Docker 映像檔上傳到 Google Cloud Storage 中。
上傳 Dcoker 映像檔 到 Cloud Storage
以下指令可將先前打包過的 Spring Boot 應用程式映像檔上傳到 Cloud Storage 中,其中 <映像檔標籤名稱> 也就是編輯部署設定檔時指定的 Spring Boot 時的映像檔標籤。
gcloud docker -- push <映像檔標籤名稱>

要確認是否上傳成功有兩個方式:
- 透過瀏覽器瀏覽 https://gcr.io/<專案 ID>/<映像檔名稱> (不含標籤)進行確認。
- 嘗試下載映像檔:若映像檔未正確上傳則會出現 not found 訊息
gcloud docker -- pull <映像檔標籤名稱>

透過設定檔啟動 Kubernetes Pod
透過指定設定檔方式啟動 Pod。
kubectl create -f k8s-deploy-config.yaml

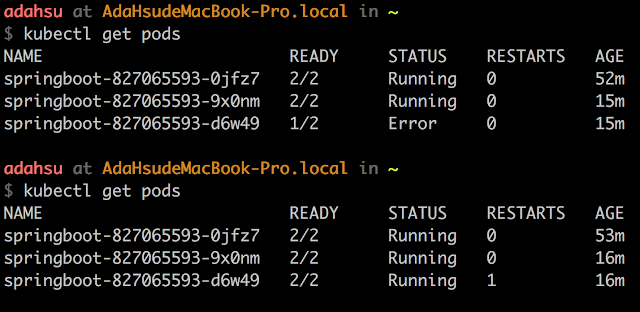
檢查 Pods 有沒有異常
Kubernetes 在啟動服務時可以透過以下指令,經檢視 RESTARTS 次數確認 Pods 啟動有無異常?
kubectl get pods

開放 Spring Boot 應用程式供外界使用
確認 Pod 沒有一直重啟後即表示相關設定沒有問題,可以正式發佈供外界存取。Kubernets 開放服務的指令是 expose,如下例:
kubectl expose deploy <deploy name> --port=<對外開放的埠號> --target-port=<Container 實際開放的埠號> --type=LoadBalancer

- <deploy name>:請參考啟動 Pod 時的輸出或是部署設定檔內的設定
- <對外開放的埠號>:這個服務實際要開放給外界連接的埠號
- <Container 實際開放的埠號>:在 Docker 映像檔中實際接受服務的埠號
當 service 被 expose 後,可以檢視該 service 的狀態 ,其中 EXTERNAL-IP 即為外界可以存取此服務的入口:
kubectl get services

實際連線可以看到 API 回覆了 Pod 的名稱:

若需要提供多個 Pods 以確保外界
有機會繼續使用服務的話,可以擴充多個 deployment 。
kubectl scale deploy <deploy name> --replicas=<Pod 數量>

此時檢查 Pod 狀態會看到產生指定個數的 Pods:

經多次存取後,可以發現 Kubernets 確實將流量分散到不同 Pod 去,雖然分流的規則不明,而且還有很高機率會導向正在重啟的 Pod 去。

在此可以呼叫第二個 API 將 Container 弄壞,然後看看 Kubernetes 會不會自動重啟新的 Container 出來。
Kubernetes 日誌追查與異常排除
檢視 Pod 日誌記錄
kubectl logs -f <Pod Name> -c <Container Name>
- <Pod Name> 即 kubectl get pods 時取得的 Name 欄位
- <Container Name> 即部署設定檔中設定的 containers 設定中的 name 欄立
範例一:檢視 springboot 的執行日誌
範例二:檢視 Cloud SQL Proxy 的執行日誌
Spring Boot 無法連線 Cloud SQL
如果 Spring Boot 無法連線到 Cloud SQL 時必然會導致 Container 崩潰,此時的問題通常是因為先前的
服務帳號沒有完整。請到
產品與服務 -->
IAM 與管理 -->
IAM 資訊主頁中確認先前建立的服務帳號是否被正確建立(包含該服務帳號的角色)。

若服務帳號沒有正確顯示在 IAM 資訊主頁中,請複製
服務帳號內完整的 EMAIL 設定到 IAM 資訊主頁內自行新增即可,角色一樣請指定為
Cloud SQL 用戶端。
與官方作法不同處說明
- 在 Cloud SQL Proxy 時並沒有建立 cloudsql-db-credentials 這個識別 (secret),這是因為這邊是由 Spring Boot 應用程式提供資料庫連線的帳密
- 若想將資料庫帳密放到 識別檔 (secret) 內的話,可以參考 cloudsql_deployment.yaml 這個範例設定部署檔
參考文件
後續的驗證與調整
有空的話會來驗證一下這些操作...
- 如何更新應用程式版本:目前不知道是不是只要上傳新的映像檔即可?
- 如何真正達到服務不中斷:Kubernetes 預設的分流規則會把流量導向隨便一個 Pod,即使該 Pod 正在重建立,此時就會出現系統無回應的錯誤訊息
- 打開 Dashboard:據說檢視 Kubernetes 運作狀態好方便... ?
關於 Load Balancer